Making shapeless practical
Recently, I’ve started using shapeless, first time for a practical task. During that I’ve met a series of obstacles, which required a lot of consultancy, source code browsing, wit and luck, hence I considered worth describing those and the way through them. I know that it is always useful to have a beginner’s feedback as it may guide the next beginners and suggest developers how to improve experience for a newcomers as with their knowledge it might be not so evident.

Implementing a simple clustering with open-source library Weka, I bumped into the need to initialize a set of Attribute objects, set it up, cluster, and then to process after clustering. That was way painful to add or modify features, as there was four places in code that needed modification, leading to a reduced productivity and possible mistakes.
With the growth of the project, bringing more entities with its own sets of features, it menaced to be just unmanageable. Then I realised that it must be a perfect case for shapeless as it is exactly supposed to facilitate wider generalization with Scala.
I tried to express all the details to provide as much context as possible and to explain all the decisions made and possibilities considered. The post happened to be quite a longread, but I hope that I hit the base for providing a valuable piece of feedback.
Definitions
First, I want to define some helper functions, first to use newly created objects in the more functional way and the second is for basic resource management:
def make[T](p: => T)(s: T => Unit) = { val v = p; s(v); v }
def using[T <: { def close() }, R](p: => T)(s: T => R): R = {
val r = s(p); Try(p.close()); r
}And as I was about to generalize clustering with weka.clusterers.SimpleKMeans over any object and its features, I also defined cluster and its unique id, as follows:
case class Id[+T](value: String)
case class Cluster[T](id: Id[Cluster[T]], objects: Array[T], typicalObject: T)where typicalObject is the centroid (object with feature values most typical for a cluster, e.g. centre point), it is not one of the objects passed initially for clustering, but rather an interpolation generated in runtime.
As Weka return the “iterable” stuff as java.util.Enumeration and receives weka.core.FastVector, in order to use Scala collections combinators I introduced the following conversions:
object Weka {
// Makes Weka `FastVector` from Scala `Iterable` implicitly
implicit def iterableToFastVector[T](iterable: Iterable[T]): FastVector =
make(new FastVector(iterable.size)) { vector =>
iterable.foreach(vector.addElement)
}
// Makes Scala `Iterator` from `java.util.Enumeration`
def enumerate[T](enumeration: java.util.Enumeration[T]) = {
Iterator.continually {
enumeration.nextElement()
} takeWhile { _ =>
enumeration.hasMoreElements
}
}
}Specialized algorithm
Initially my specialized algorithm, lets say on Example class instances,
case class Example(
feature1: Option[Long],
feature2: Option[Double],
feature3: Option[String],
feature4: Option[Long],
feature5: Option[String],
feature6: Option[Boolean])had method signature pretty much like that,
def kMeans(objectsList: List[Example]): Seq[Cluster[Example]]
Which returned Nil for empty objectsList and for non-empty did the following:
Collected some statistics of the data input to determine the number of clusters and possible values of the discrete features (in this case — of types String and Boolean),
val feature3Values = objects.flatMap(_.feature3).distinct
val feature5Values = objects.flatMap(_.feature5).distinct
val feature6Values = objects.flatMap(_.feature6).distinct.map(_.toString)
val cardinality = feature3Values.size + feature5Values.size + feature6Values.size
val clusterGrowthFactor = 12
val clusterAmount = math.min(cardinality/clusterGrowthFactor, objects.size-1)
After that, created the feature vector:
val features = Seq(
new Attribute("feature1", Seq()),
new Attribute("feature2", Seq()),
new Attribute("feature3", feature3Values),
new Attribute("feature4", Seq()),
new Attribute("feature5", feature5Values),
new Attribute("feature6", feature6Values)
)
Next, initialised the algorithm: create SimpleKMeans object, fill in the instances that will be clustered with the actual features values with the specific conversions for each feature type, and provide options (e.g. clusterAmount etc):
val kmeans = make(new SimpleKMeans()) { clusterer =>
val instances = make(new Instances("objects",
iterableToFastVector(features), objects.size)) { instances =>
objects foreach { obj =>
instances.add(make(new Instance(features.size)) { example =>
if(obj.feature1.isDefined)
example.setValue(features(0), obj.feature1.get.toDouble)
else example.setMissing(features(0))
if(obj.feature2.isDefined)
example.setValue(features(1), obj.feature2.get)
else example.setMissing(features(1))
if(obj.feature3.isDefined)
example.setValue(features(2), obj.feature3.get)
else example.setMissing(features(2))
if(obj.feature4.isDefined)
example.setValue(features(3), obj.feature4.get.toDouble)
else example.setMissing(features(3))
if(obj.feature5.isDefined)
example.setValue(features(4), obj.feature5.get)
else example.setMissing(features(4))
if(obj.feature6.isDefined)
example.setValue(features(5), obj.feature6.get.toString)
else example.setMissing(features(5))
})
}
}
clusterer.setNumClusters(clusterAmount)
clusterer.setPreserveInstancesOrder(true)
clusterer.buildClusterer(instances)
}
Then, we are launching an algorithm and grouping objects by cluster:
val centroids = enumerate(kmeans.getClusterCentroids.enumerateInstances())
val objectsByCluster = kmeans.getAssignments.zip(objects).groupBy(_._1)
Eventually, Cluster objects are created and centroids are extracted:
val clusters = centroids.zipWithIndex map {
case (instance, index) =>
Cluster[Example](
Id(index.toString),
objectsByCluster.getOrElse(index, Array[(Int, Example)]()).map(_._2),
typicalObject = Example(
Option(instance.asInstanceOf[Instance].value(0).toLong),
Option(instance.asInstanceOf[Instance].value(1)),
Option(instance.asInstanceOf[Instance].stringValue(3)),
Option(instance.asInstanceOf[Instance].value(4).toLong),
Option(instance.asInstanceOf[Instance].stringValue(5)),
Option("true".equals(instance.asInstanceOf[Instance].stringValue(6))))
)
} toSeq
Option(clusters).filterNot(_.isEmpty && objects.isEmpty) getOrElse {
List(Cluster[Example](Id("0"), objects.toArray, objects.head))
}With the fallback in the very end, we are done. As it might be noticed above, there are four places where features are enumerated explicitly with some type dependent treatment, those are:
- Taking the distinct values;
Attributes creation;- Filling in the
Instances; - Centroid extraction.
It is clear that it must be painful for different types of input objects and non-trivial how to generalize it in a way to preserve type safety (unlike reflection and dynamic typing).
General algorithm
Well, seems like shapeless is to the rescue! To preserve type-safety while iterating over the case class fields HList is definitely the right abstraction to work with and Generic to convert case classes to HList, back and forth. Actually, I took LabelledGeneric to convert case classes to “records”, which are nothing more that HLists with values tagged with field names (read further to some intuitive explanation of that). I wanted to use my case class field names as the Weka Attribute names, instead of generated ones for the better debugging capabilities.
So, I created generic and converted all of my objects to the records,
val objectGeneric = new LabelledGeneric[Example]
val generics = objects.map(objectGeneric.to)After that I needed to generalize to exclude direct Example class reference, but let’s omit this for simplicity for a while.
Well, it is time to calculate statistics for the data. The idea is to make an HList of List with at most one value (when it presented in the input object) for each record and the to fold those records, calculating union for its feature values. Soo, I was needed a few combinators for that. First obstacle was that there is no combinators defined at shapeless.HList and I found no reference docs of which combinators are present. Hm, after some search through the source code and googling I found that combinators for records, hlists, nat etc are provided implicitly (for HLists with shapeless.HListOps) and are placed at shapeless.ops._. Thus, importing,
import shapeless.ops.hlist._Well, I checked that and found that there are map and zip presented. Fine, the algorithm might look like,
val distinctValues = generics.map(_.map(getDistinctValues))
.reduce((dv1, dv2) => (dv1 zip dv2).map(combineValues))Ok, but how to define function that maps over the HList? HList might contain values of different types, e.g. [String, Long, Boolean]. Therefore, function to preserve type-safety must have different implementations for different types of values returning yet different types. Scala functions definitely don’t provide this. That is why polymorphic functions are helpful. I can’t remember where I’ve seen this picture, but it explains how they work pretty well:
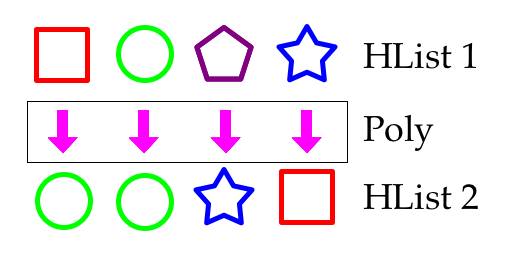
To define a Poly there should be an object created with different functions for different argument types, where the best match for arguments is found with implicit search. Thus, for getDistinctValues we are having those four options for Double, Boolean, String, Long for fields of different types:
object getDistinctValues extends Poly1 {
implicit def caseFieldDouble [K] = at[FieldType[K, Option[Double]]] { field => … }
implicit def caseFieldBoolean[K] = at[FieldType[K, Option[Boolean]]] { field => … }
implicit def caseFieldString [K] = at[FieldType[K, Option[String]]] { field => … }
implicit def caseFieldLong [K] = at[FieldType[K, Option[Long]]] { field => … }
}The next issue for me was that the field does not contain a key. Thus, no way to use key value during the mapping of this field. This happens as the keys are tags and are available at the compile time only. Because of this, runtime evaluation of the field object haven’t shown any presence of the key. Solution came from my colleague, he explained that I need to define an implicit parameter of type Witness.Aux[K] for my functions that will provide me the key value. Key comes literally out of nowhere and I found neither list nor explanation of these Auxes. So it is not clear what functionality you could get out of those, and you need to browse different source code packages in order to collect different Aux implementation and get some understanding. At least I’ve got that working, so the getDistinctValues and combineValues look like following,
object getDistinctValues extends Poly1 {
implicit def caseFieldDouble [K](implicit wk: Witness.Aux[K]) =
at[FieldType[K, Option[Double]]] { field => wk.value -> List[Double]() }
implicit def caseFieldBoolean[K](implicit wk: Witness.Aux[K]) =
at[FieldType[K, Option[Boolean]]] { field => wk.value -> field.toList }
implicit def caseFieldString [K](implicit wk: Witness.Aux[K]) =
at[FieldType[K, Option[String]]] { field => wk.value -> field.toList }
implicit def caseFieldLong [K](implicit wk: Witness.Aux[K]) =
at[FieldType[K, Option[Long]]] { field => wk.value -> List[Long]() }
}
object combineValues extends Poly1 {
implicit def caseAny[K,V] = at[((K, List[V]), (K, List[V]))](fields =>
fields._1._1 -> (fields._1._2 ++ fields._2._2).distinct)
}Poly combineValues has just one case as getDistinctValues produces the same result type List for all arguments. In this case a simple monomorphic might be enough. However, as we are continuing to work with HLists we still need to define a Poly. That is just concatenating two lists of different records and excluding the repetitive values.
After that we came to the statistics calculation, that is pretty straitforward,
val cardinality = distinctValues.map(size).toList.reduce(_ + _)
val clusterAmount = math.min(cardinality/clusterGrowthFactor, objects.size - 1)except that, again, we need to define custom Poly function size as we are working with HLists (that might be quite useful to have an implicit from usual monomorphic functions to a polymorphic with just one case, if that is possible at all):
object size extends Poly1 {
implicit def caseList[K,V] = at[(K, List[V])](_._2.size)
}So far so good, first part is done! And we are going to build features. There are no new conceptions here, just one new Poly named createAttribute (key values are already available in runtime due to the previous mapping):
val features = distinctValues.map(createAttribute)
object createAttribute extends Poly1 {
implicit def caseDouble [K] = at[(K, List[Double])] { values =>
new Attribute(values._1.toString) }
implicit def caseBoolean[K] = at[(K, List[Boolean])] { values =>
new Attribute(values._1.toString, values._2.map(_.toString)) }
implicit def caseString [K] = at[(K, List[String])] { values =>
new Attribute(values._1.toString, values._2) }
implicit def caseLong [K] = at[(K, List[Long])] { values =>
new Attribute(values._1.toString, Seq()) }
}Ok, we’ve come to the configuration of the clustering algorithm. Now we need to transform the HList to some regular list to feed it to the Instances ‘ constructor not loosing the type information. For that purpose unify function is very handy. With toList it will produce List of the least upper bounds (List[Attribute] in our case):
def makeInstances = new Instances("objects", features.unify.toList, objects.size)And after that we need to add instance to this object. Instance creation requires the number of features in this instance, but features is an HList and its length method returns Nat which is a peano number available in compile time and it is not the easiest thing to convert it to an Int. Fortunately there is runtimeLength method on HList implemented doing just this!
To fill instance with input object data, we’re going to combine the newly created instance, features HList and specific input object. Features and object combined smoothly as both are HLists and have zip. Although, passing instance to the Poly filing that instance was tricky for me, because it is the same object to all the features. I’ve tried to pass it as an implicit parameter, but had some mysterious compiler errors. Currying on Polys is also tricky as those are objects and not accepting constructor parameters. Finally, I found method zipConst that matched best. Eventually, algorithm initialization code it as follows,
val kmeans = make(new SimpleKMeans()) { clusterer =>
val instances = make(makeInstances) { instances =>
objects foreach { obj =>
instances.add(make(new Instance(features.runtimeLength)) { instance =>
features.zip(objectGeneric.to(obj)).zipConst(instance).map(fillInstance)
})
}
}
clusterer.setNumClusters(clusterAmount)
clusterer.setPreserveInstancesOrder(true)
clusterer.buildClusterer(instances)
}Implementation for fillInstance tackles with the Java API that actually setting value to instance by producing an effect. To mimic functional behaviour the instance filled with value returned from the fillInstance in fve._2. There is again different treatment for different types, the only difference though, lies in the value conversion before passing it to setValue method:
object fillInstance extends Poly1 {
implicit def caseDouble[K] =
at[((Attribute, FieldType[K, Option[Double]]), Instance)] { fve =>
if(fve._1._2.isDefined) fve._2.setValue(fve._1._1, fve._1._2.get)
else fve._2.setMissing(fve._1._1); fve._2
}
implicit def caseBoolean[K] =
at[((Attribute, FieldType[K, Option[Boolean]]), Instance)] { fve =>
if(fve._1._2.isDefined) fve._2.setValue(fve._1._1, fve._1._2.get.toString)
else fve._2.setMissing(fve._1._1); fve._2
}
implicit def caseString[K] =
at[((Attribute, FieldType[K, Option[String]]), Instance)] { fve =>
if(fve._1._2.isDefined) fve._2.setValue(fve._1._1, fve._1._2.get)
else fve._2.setMissing(fve._1._1); fve._2
}
implicit def caseLong[K] =
at[((Attribute, FieldType[K, Option[Long]]), Instance)] { fve =>
if(fve._1._2.isDefined) fve._2.setValue(fve._1._1, fve._1._2.get.toDouble)
else fve._2.setMissing(fve._1._1); fve._2
}
}Launching the clustering algorithm is all the same,
val centroids = enumerate(kmeans.getClusterCentroids.enumerateInstances())
val objectsByCluster = kmeans.getAssignments.zip(objects).groupBy(_._1)And by now building clusters is what it is left. First, let’s remember that there should be centroid constructed for each cluster. That is an instance of the input object class (e.g. Example). I know of no ways in Scala to model polymorphic class constructors except providing a factory method, which is a burden for the algorithm api client, though I found a trick to avoid that burden. As input objects list is not empty (it is checked by the condition at the very beginning), there is a head, and it might be used as an initial object to map it to HList, fill with values from the corresponding instance and convert back to the input object class (e.g. Example).
To obtain a value from the instance an index of a feature is needed, that is why I was searching for zipWithIndex on HList and it wasn’t there. Great help came from the community. Travis Brown implemented that and posted on Stack Overflow.
Applying this zipWithIndex on reference and adding instance with zipConst, as mentioned above, we are able to apply Poly named fitWithInstanceData producing record for the instance and map back to Example with objectGeneric.from:
val reference = objectGeneric.to(objects.head)
val typicalObject = objectGeneric.from(
zipWithIndex(reference)
.zipConst(instance.asInstanceOf[Instance])
.map(fitWithInstanceData))
object fitWithInstanceData extends Poly1 {
implicit def caseDouble[K, N <: Nat: ToInt] =
at[((FieldType[K, Option[Double]], N), Instance)] { fv =>
field[K](Option(fv._2.value(toInt[N]))) }
implicit def caseBoolean[K, N <: Nat: ToInt] =
at[((FieldType[K, Option[Boolean]], N), Instance)] { fv =>
field[K](Option("true".equals(fv._2.stringValue(toInt[N])))) }
implicit def caseString[K, N <: Nat: ToInt] =
at[((FieldType[K, Option[String]], N), Instance)] { fv =>
field[K](Option(fv._2.stringValue(toInt[N]))) }
implicit def caseLong[K, N <: Nat: ToInt] =
at[((FieldType[K, Option[Long]], N), Instance)] { fv =>
field[K](Option(fv._2.value(toInt[N]).toLong)) }
}There is one implementation detail worth mentioning. As I was mapping the records processing the fields, I was needed to construct fields back with the same keys but different values. Receiving values with Witness.Aux[K] and then using ->> operator haven’t helped as the value loses type information and it is not provable that it is the same K. Fortunately, I was making the finishing touches during Scala Days ’15, so I was able to ask Miles. He suggested using some hardly noticeable function in the source code, namely field[K]. That was exactly what I was searching for. Unfortunately, there is no trace of this function description in the documentation.
Well, now we are picking that typicalObject and mapping the centroids returned by KMeans to the Cluster instances:
val clusters = centroids.zipWithIndex map { case (instance, index) =>
Cluster[T](
Id(index.toString),
objectsByCluster.getOrElse(index, Array[(Int, T)]()).map(_._2),
typicalObject)
} toSeqWeka gives no clusters for a single object, hence we are providing fallback for uniformity, the final result is, as follows,
Option(clusters).filterNot(_.isEmpty && objects.isEmpty) getOrElse {
List(Cluster[T](Id("0"), objects.toArray, objects.head))
}Well! That must work fine! But remember, as I mentioned earlier, LabelledGeneric was created with specific Example class parameter. It is time to generalize over that, along with the necessity to have an enclosure (function and class) for the code aforementioned.
Enclosure and manual type inference
It is impossible to create LabelledGeneric[T] with regular constructor, like that:
val objectGeneric = new LabelledGeneric[T]It might be obtained just as an implicit parameter of type LabelledGeneric.Aux[T,R]. Along with that, new type parameter R (for “representation”) is required. We must declare this and at least specify that it is going to be an HList (thanks to xeno_by for clarification). Thus, complete enclosure for the algorithm looks like,
class KMeans[T : ClassTag, R <: HList]
(objectsList: List[T], clusterGrowthFactor: Int = 12)
(implicit objectGeneric: LabelledGeneric.Aux[T, R]) {
def clusters: Seq[Cluster[T]] = objectsList match {
case Nil => Nil
case objects =>
...
}
}Then it happens that type R doesn’t contain any information on whether this HList is able to do something, e.g. be mapped (Mapper.Aux), zipped (Zip.Aux), asked of length (Length.Aux) etc. Each combinator on that needs some kind of a special evidence, that might be received as implicit parameters and its evidence types all must be enumerated at the type parameters. There must be as many type parameters, as many intermediate steps in the algorithm and all those must be commutated well (see the code for clarification on what I mean by the “commutation”). Some combinators require also specific type parameters, like Nat or, for example Mapper.Aux required types of the functions that are going to map an HList, hence all the Poly definitions where moved to a separate object Functions and the code turned to the following,
class KMeans[T : ClassTag, R <: HList, R2 <: HList, R3 <: HList, R4 <: HList,
R5 <: HList, R6 <: HList, R7 <: HList, R8 <: HList, R9 <: HList,
R10 <: HList, R11 <: HList, R12 <: HList, L <: Nat]
(objectsList: List[T], clusterGrowthFactor: Int = 12)
(implicit objectGeneric: LabelledGeneric.Aux[T, R],
gdvm: Mapper.Aux[Functions.getDistinctValues.type, R, R2],
dvz: Zip.Aux[R2 :: R2 :: HNil, R3],
cvm: Mapper.Aux[Functions.combineValues.type, R3, R2],
sm: Mapper.Aux[Functions.size.type, R2, R4],
vtt: ToTraversable.Aux[R4, List, Int],
cam: Mapper.Aux[Functions.createAttribute.type, R2, R5],
fu: Unifier.Aux[R5, R6],
uft: ToTraversable.Aux[R6, List, Attribute],
len: Length.Aux[R, L],
fz: Zip.Aux[R5 :: R :: HNil, R7],
fgez: ZipConst.Aux[Instance, R7, R10],
gem: Mapper.Aux[Functions.fillExample.type, R10, R11],
rng: Range.Aux[nat._0, L, R8],
rfz: Zip.Aux[R :: R8 :: HNil, R9],
riz: ZipConst.Aux[Instance, R9, R12],
rfm: Mapper.Aux[Functions.fitWithInstanceData.type, R12, R]) {
def clusters: Seq[Cluster[T]] = objectsList match {
case Nil => Nil
case objects =>
...
}
}As you may imagine, it was a way tough to implement that. I had plenty of time to think when was matching those R’s together. And all that time I was thinking that I am doing the compiler’s job, namely type inference. I have no clear idea of how to return that back to the compiler, but hopefully there is one, maybe macros are to the rescue?
Conclusion
It happened that for my single entity with a bunch of fields there was more of this general code than I had specific code. That was peculiar with the shapeless’ promise to scrap down the boilerplate. One idea I’ve came up with is similar to the Expression problem: there is a trade-off between general and specialized code. Writing specialized code is more laconic when algorithms are complex and there are just a few of data structures, and more verbose when algorithm is simple and there are plenty of the data structures, general code is just the opposite. With specialised code you’re to tackle more with each of the data field (data), and with general with each algorithm step (codata). I would call that “Generality problem”. For optimum, code generality must gravitate to the Data-Code ratio, and shapeless is the way to push that ratio.
Regarding shapeless, it is obviously cool library but lacks some sufficient documentation. Either reference of all the available combinators and Auxes, or some “concepts” paper with description of the core ideas and related source code packages to browse. Otherwise users will be doomed to learn all of its implementation details even for the simple cases. What, according to Dick Wall, makes using of a library pointless. Effort to write such a paper seems feasible and maybe I’ll do that myself at some point in the future.
All the source code from this post might be found at the github project.
Hopefully, that post was useful.